Background Knowledge
Reference: https://www.timescale.com/
- TSDB is a service contain Continuous Aggregate, Hypertable functions on PostgreDB.
- Using saving continuous data.
| Continuous Aggregate | Hypertable |
|---|---|
| • For fast query to bigdata, Using Materialzed View • good for candle data. |
• time-base partitioning. • make data to batch units |
- HyperTable
- 특정 테이블이 Timestamp 혹은 DATE타입의 필드를 포함할 경우 시계열 테이블(일정 시간 간격으로 배치된 데이터)로 인식한다.
- 시계열 테이블에서 데이터 변경점이 발생할 때마다 테이블을 여러 덩어리(chunked)로 쪼개는 최적화 작업을 백그라운에서 자동으로 수행된다.
- 이를 통해, 가장 최근의 덩어리에 해당하는 데이터와 인택스가 메모리에 유지되어 대량의 데이터가 유입되어도 꾸준하게 빠른 성능의 CRUD가 수행된다.
- 백그라운드에선느 내부 알고리즘의 판단에 의해 자동으로 특정시일이 자난 덩어리를 압축한다. 이를 통해 최신 데이터의 유입 성능을 보장하면서(노드 1개당 초당 10만개 raw 유입 보장) 오래된 데이터를 압축하여 전체 스토리지 공간을 절약할 수 있다. (200T → 16T)
- Hypertable은 사용자가 지정 혹은 기본 값으로 설정된
chunk_time_interval(기본 값 7일) 값을 통해 테이블에 저장된 데이터를 chunk 단위로 묶는다. 이렇게 묶인 집합을 hypertable이라고 함.
정리하면 Hypertable은 chunk의 묶음이고, chunk는 Postgres의 table입니다. hypertable은 상위 테이블 chunk는 하위 테이블입니다.
- 용도 : 센서 / 주식 / GPS 등의 시간경과를 다루는 데이터
Test
→ TSDB’s special functions.
Timescale Documentation | Tutorials
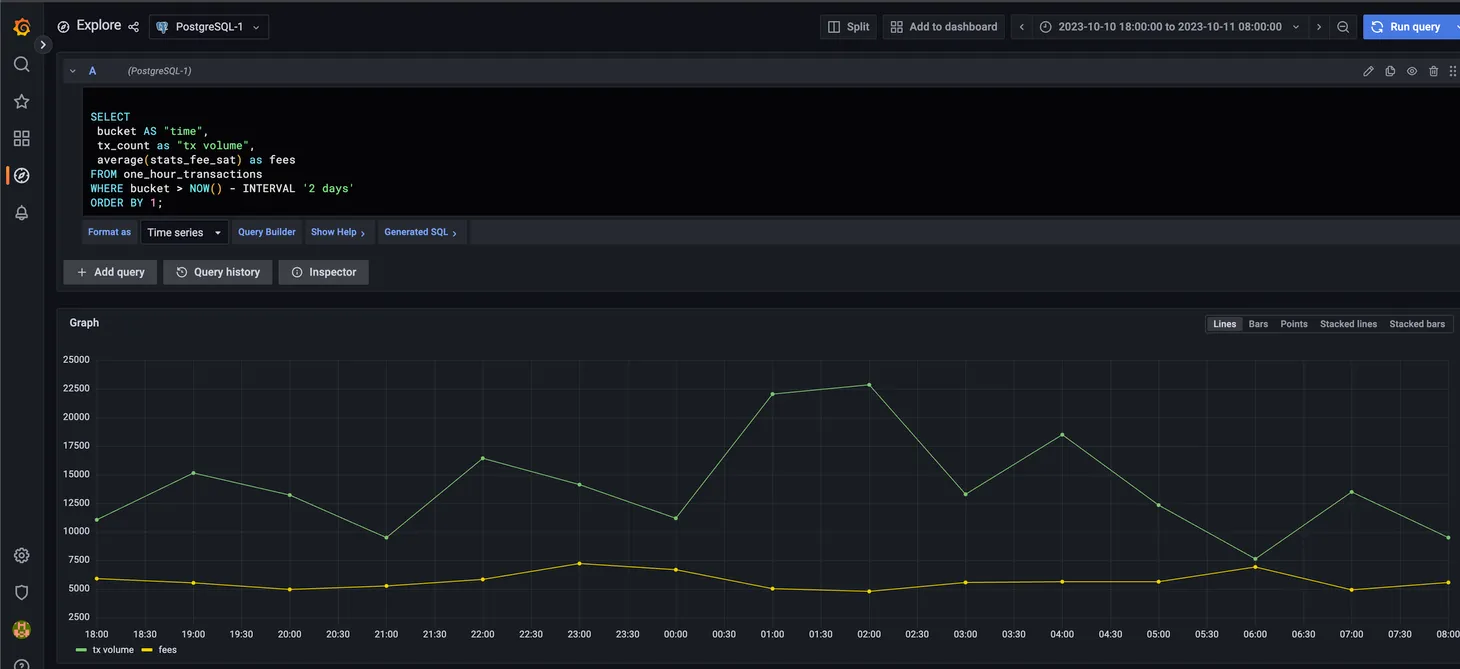
- Cryptocurrency : the Bitcoin blockchain’s transaction ETL
'데이터 엔지니어링 > DB' 카테고리의 다른 글
| DB 및 grafana 생성 및 데이터 마이그레이션 (0) | 2025.08.10 |
|---|---|
| [timescaleDB] Continuous aggregates 사용기 (1) | 2025.08.10 |
| Postgres DB는 이렇게 생겼다! (0) | 2025.08.10 |


