벡터 DB 선택 과정
AI 프로젝트를 진행하면서 벡터 DB를 선정해야 할 일이 생겼다.
빠르게 구축하고 테스트해보는 것이 목적이었기에 AWS Bedrock을 활용해보기로 했고, 스터디가 충분하지 않았기 때문에 Bedrock 서비스에서 제공하는 DB(Postgres, OpenSearch) 두 가지를 확인했다.
처음에는 참고자료가 많고 쿼리도 자유로운 OpenSearch를 사용하려 했지만, 다른 개발자(DevOps, 백엔드)와의 소통을 위해 Postgres를 사용하기로 결정했다.
(사실 데이터를 보는 건 Postgres가 훨씬 편하다… 그래서 나도 postgres를 선택하는 것에 동의했다.)


개발을 진행하고 있는데 갑자기...
개발을 진행하던 중, 코사인 유사도를 이용한 분석 시 Postgres와 OpenSearch에 따라 결과가 달라지지 않을까 하는 의견이 나왔다.
OpenSearch는 검색에 특화되어 있으므로 당연히 다르게 나올 것 같다고 다른 개발자가 말했다.
“같은 데이터인데 코사인 유사도가 Postgres에서는 1, OpenSearch에서는 2가 나오는게 이상하지 않아여..?”
어디서 부터 설명을 해야할까... 하...
물론 검색 방법을 바꾸거나 일부 조건을 설정하면 다르게 나올 수 있지만, 기본적으로는 동일한 결과가 나오는게 내 의견이다.
그를 설득하라!...
이제 그 개발자를 설득해야 하는 상황이었다.
이 사람을 어떻게 설득해야 할까... 어떻게 해야 프로젝트가 이상한 방향으로 안 흘러가
조건.
- 많은 사람들 앞에서 발표를 함.
- DB를 자주 안접해본 사람들도 있음.
- 정보의 전달이 목적ㅇ미...
-
따라서 직접 보여주는 방법이 최선이었다. 기왕이면 모델 비교와 청킹 전략도 함께 보여주었다.
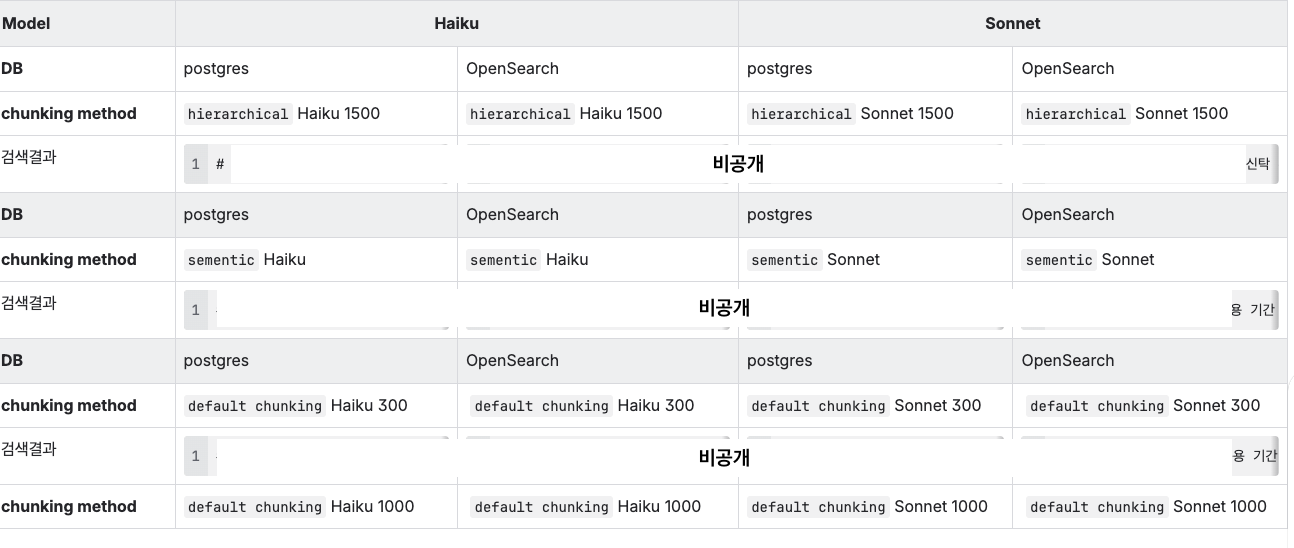
실험 방법
- Postgres와 OpenSearch를 올린다.
- 같은 데이터(마이그레이션)를 동일한 방법으로 청킹(chunking)한다.
- 한 번은 Haiku로, 다른 한 번은 Sonnet으로 진행
- 청킹 방법: 계층적, 시맨틱, Fix 방식
- 검색 결과를 보여준다.
배운 점
이번 발표를 통해 AI 관련 학습뿐만 아니라 발표 및 설득 방법도 조금 배운 것 같다.
청킹 전략과 모델 비교를 함께 보여주면서, 다른 개발자들에게도 다양한 시각을 제공했다.
예전같으면 엄청 화를 내면서 말했겠지만 흥분할 수록 신뢰도가 떨어지고, 실수 할 수 있다.
내가 평소 의사소통 개선을 위해 관련 도서를 자주 읽은 게 이번 프로젝트에서 도움이 되었다...
'데이터 엔지니어링 > AI' 카테고리의 다른 글
| 대량의 PDF 문서, 어떻게 vector DB에 적재할까? (0) | 2025.08.24 |
|---|---|
| [VectorDB] Anthropic 전략, Contextual Retrieval 성능측정 (1) | 2025.08.20 |
| 호옥시... tmux 아세요? 옛날에 tmux로 여러 ai model 훈련시킨... (1) | 2025.08.11 |
| 예전에는 이렇게 ai를 했었다. (1) | 2025.08.11 |


